PC Generation
PC gen is responsible for generating the next program counter. All
program counters are logical addressed. If the logical to physical
mapping changes a fence.vm instruction should flush the pipeline and TLBs.
This stage contains speculation on the branch target address as well as the information if the branch is taken or not. In addition, it houses the branch target buffer (BTB) and a branch history table (BHT).
If the BTB decodes a certain PC as a jump the BHT decides if the branch
is taken or not. Because of the various state-full memory components
this stage is split into two pipeline stages. PC Gen communicates with
the IF via a handshake signal. Instruction fetch signals its readiness
with an asserted ready signal while PC Gen signals a valid request by
asserting the fetch_valid signal.
The next PC can originate from the following sources (listed in order of precedence):
Default assignment: The default assignment is to fetch PC + 4. PC Gen always fetches on a word boundary (32-bit). Compressed instructions are handled in a later pipeline step.
Branch Predict: If the BHT and BTB predict a branch on a certain PC, PC Gen sets the next PC to the predicted address and also informs the IF stage that it performed a prediction on the PC. This is needed in various places further down the pipeline (for example to correct prediction). Branch information which is passed down the pipeline is encapsulated in a structure called
branchpredict_sbe_t. In contrast to branch prediction information which is passed up the pipeline which is just calledbp_resolve_t. This is used for corrective actions (see next bullet point). This naming convention should make it easy to detect the flow of branch information in the source code.Control flow change request: A control flow change request occurs from the fact that the branch predictor mis-predicted. This can either be a ‘real’ mis-prediction or a branch which was not recognized as one. In any case we need to correct our action and start fetching from the correct address.
Return from environment call: A return from an environment call performs corrective action of the PC in terms of setting the successive PC to the one stored in the
[m|s]epcregister.Exception/Interrupt: If an exception (or interrupt, which is in the context of RISC-V systems quite similar) occurs PC Gen will generate the next PC as part of the trap vector base address. The trap vector base address can be different depending on whether the exception traps to S-Mode or M-Mode (user mode exceptions are currently not supported). It is the purpose of the CSR Unit to figure out where to trap to and present the correct address to PC Gen.
Pipeline Flush because of CSR side effects: When a CSR with side-effects gets written we need to flush the whole pipeline and start fetching from the next instruction again in order to take the up-dated information into account (for example virtual memory base pointer changes).
Debug: Debug has the highest order of precedence as it can interrupt any control flow requests. It also the only source of control flow change which can actually happen simultaneously to any other of the forced control flow changes. The debug unit reports the request to change the PC and the PC which the CPU should change to.
This unit also takes care of a signal called fetch_enable which
purpose is to prevent fetching if not asserted. Also note that no
flushing takes place in this unit. All the flush information is
distributed by the controller. Actually the controller’s only purpose is
to flush different pipeline stages.
Branch Prediction
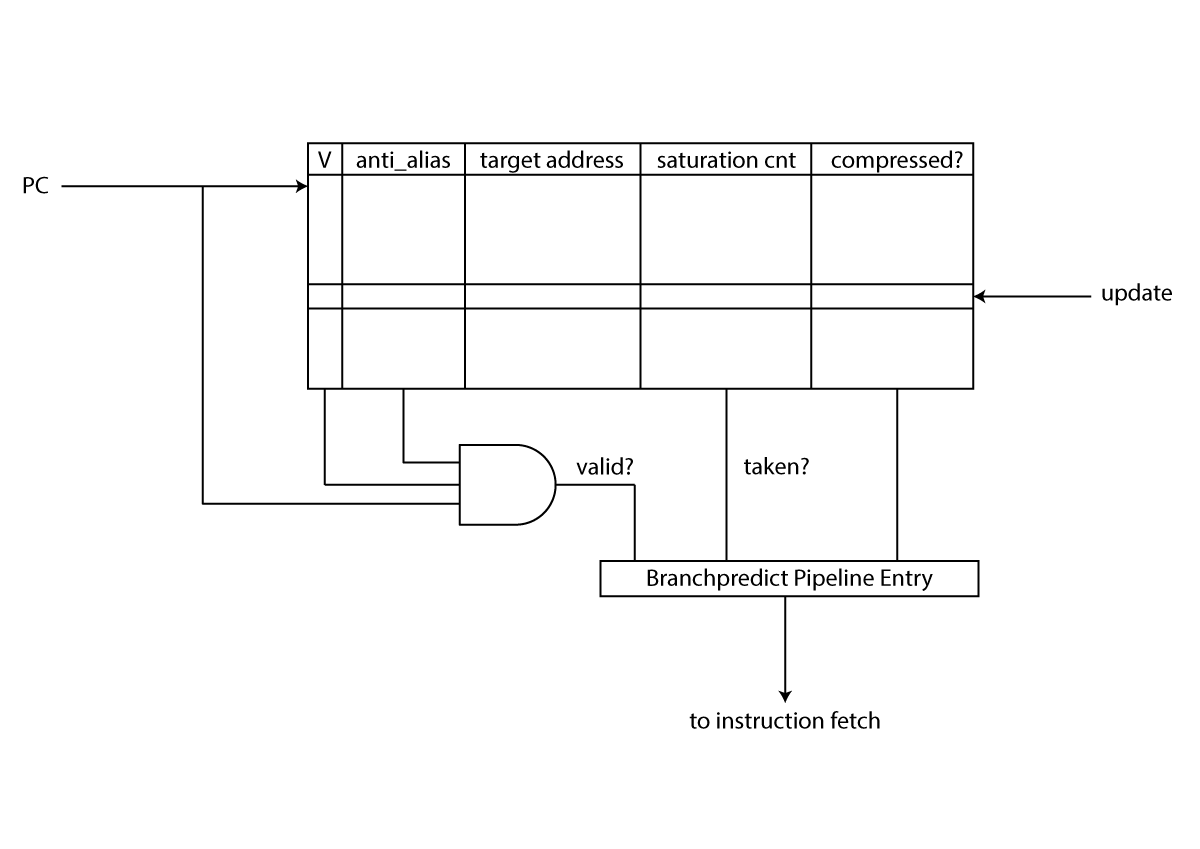
All branch prediction data structures reside in a single register-file like data structure. It is indexed with the appropriate number of bits from the PC and contains information about the predicted target address as well as the outcome of a configurable-width saturation counter (two by default). The prediction result is used in the subsequent stage to jump (or not).
In addition of providing prediction result the BTB also updates its information on mis-predictions. It can either correct the saturation counter or clear the branch prediction entry. The latter is done when the branch unit saw that the predicted PC didn’t match or an when an instruction with privilege changing side-effect is committing.
The branch-outcome and the branch target address are calculated in the same functional unit therefore a mis-prediction on the target address is as costly as a mis-prediction on the branch decision. As the branch unit (the functional unit which does all the branch-handling) is already quite critical in terms of timing this is a potential improvement.
As Ariane fully implements the compressed instruction set branches can also happen on 16-bit (or half word) instructions. As this would significantly increase the size of the BTB the BTB is indexed with a word aligned PC. This brings the potential draw-back that branch-prediction does always mis-predict on a instruction fetch word which contains two compressed branches. However, such case should be rare in reality.
A trick we played here is to take the next PC (e.g.: the word aligned PC of the upper 16-bit of this instruction) of an un-aligned instruction to index the BTB. This naturally allows the the IF stage to fetch all necessary instruction data. Actually it will fetch two more unused bytes which are then discarded by the instruction re-aligner. For that reason we also need to keep an additional bit whether the instruction is on the lower or upper 16-bit.
For branch prediction a potential source of unnecessary pipeline bubbles is aliasing. To prevent aliasing from happening (or at least make it more unlikely) a couple of tag bits (upper bits from the indexed PC) are used and compared on every access. This is a trade-off necessary as we are lacking sufficiently fast SRAMs which could be used to host the BTB. Instead we are forced to use register which have a significantly larger impact on over all area and power consumption.